


#25 GenAI Misuses and Prompt Hacking (part 1)
Tactics and Insights from Real-world Data



Good morning, everyone!
Today we're exploring the misuse of GenAI and the growing need for more robust security measures in integrating LLMs into software systems. As organizations increasingly adopt AI-driven solutions, the potential risks and threats continue to increase. Google DeepMind’s recent June 2024 paper offers interesting insights into the various tactics used to bypass AI’s safeguards and guardrails.
Understanding and mitigating these risks is important if you're a leader overseeing these systems. As the paper outlines, the misuse of LLMs isn't just theoretical—it's happening now, with real-world implications for businesses, governments, and individuals, from financial fraud to reputational harm.
GenAI Misuse and Prompt Hacking
We often think of prompt hacking or jailbreaking as isolated incidents, but the data tells us something different, with many ways to harm others through generating content! For instance, “prompt injection,” which we discussed in our recent guardrail iteration, is not even among the top tactics reported in the study, with the first ones being impersonation, scaling & amplification, and falsification, among others.
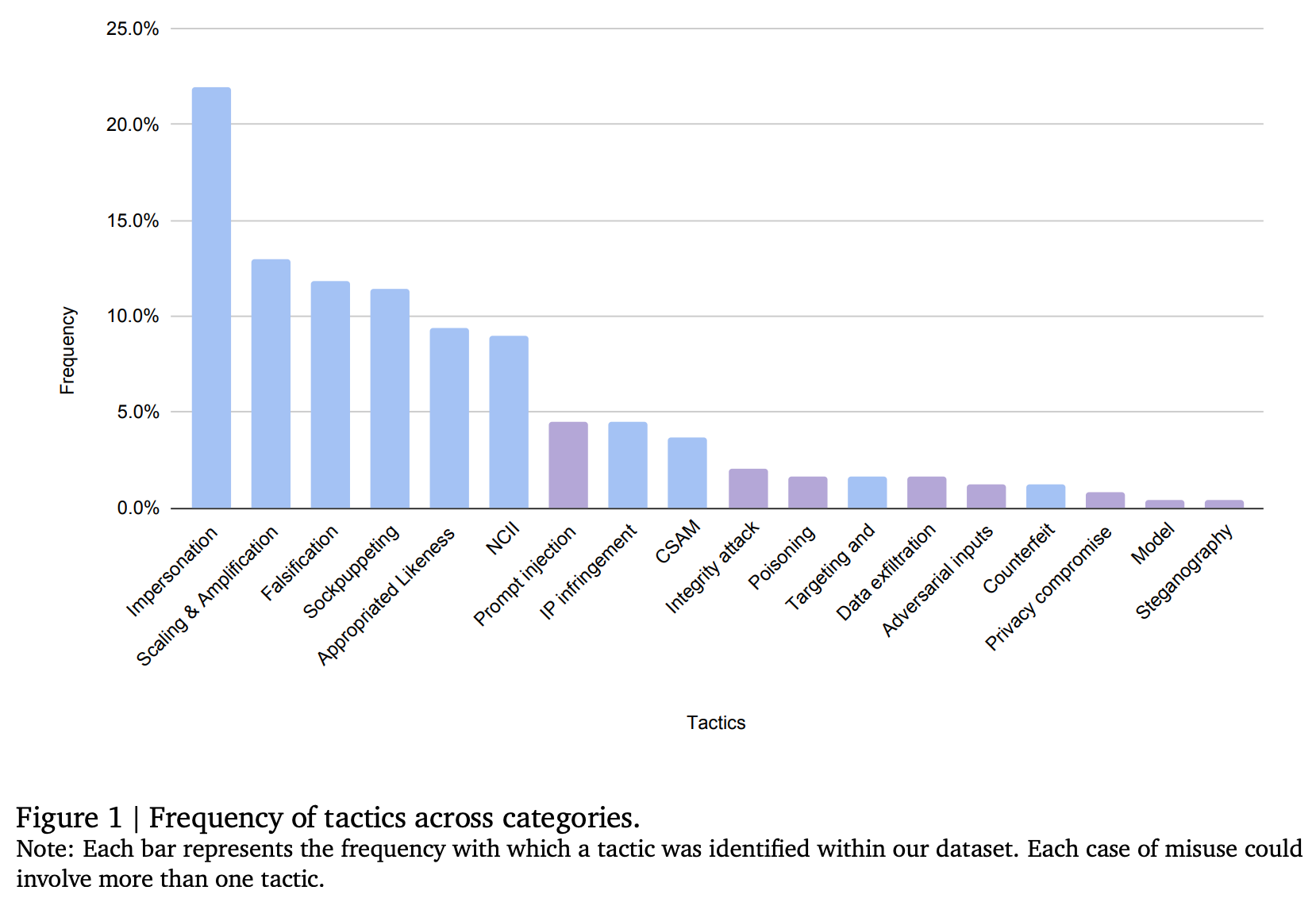
Let’s break down these most frequent tactics (the ones to look for when building GenAI systems):
Impersonation: AI-generated deepfakes of public figures, from political leaders like Biden and Trump to celebrities, have been used to manipulate public opinion and cause reputational harm. AI systems can now mimic voices, images, and even mannerisms, making it harder to distinguish real from fake.
Scaling & Amplification: This involves automating the generation and distribution of misleading content. The ability to scale the creation of misleading media at such a volume is concerning. Bots and fake personas can flood social platforms, spreading disinformation more efficiently than ever.
Falsification: We’re seeing a surge in fabricated evidence—AI-generated documents, images, and videos used to deceive audiences. Think of those fabricated images of protests or events that never occurred; they’re becoming more convincing by the day.
Sockpuppeting: Creating synthetic online personas or accounts to deceive or manipulate. These fake accounts can influence opinions, spread misinformation, or stimulate grassroots support for a cause.
… (we attached a complete list of the various attacks with links to external examples of them from the paper at the end of the newsletter)
These tactics aren’t just theoretical. They represent real-world misuse cases that are already happening, from financial fraud and disinformation to personal harassment. Notably, many attacks don’t require sophisticated technical expertise; they need simple access to generative AI tools.
Attackers aren’t limited to using just text. The analysis below shows they exploit multiple modalities—images, audio, video, and text. As GenAI technology expands, attackers can use different media types, making safeguarding even more complex.
Here's a breakdown of the modalities associated with each tactic:
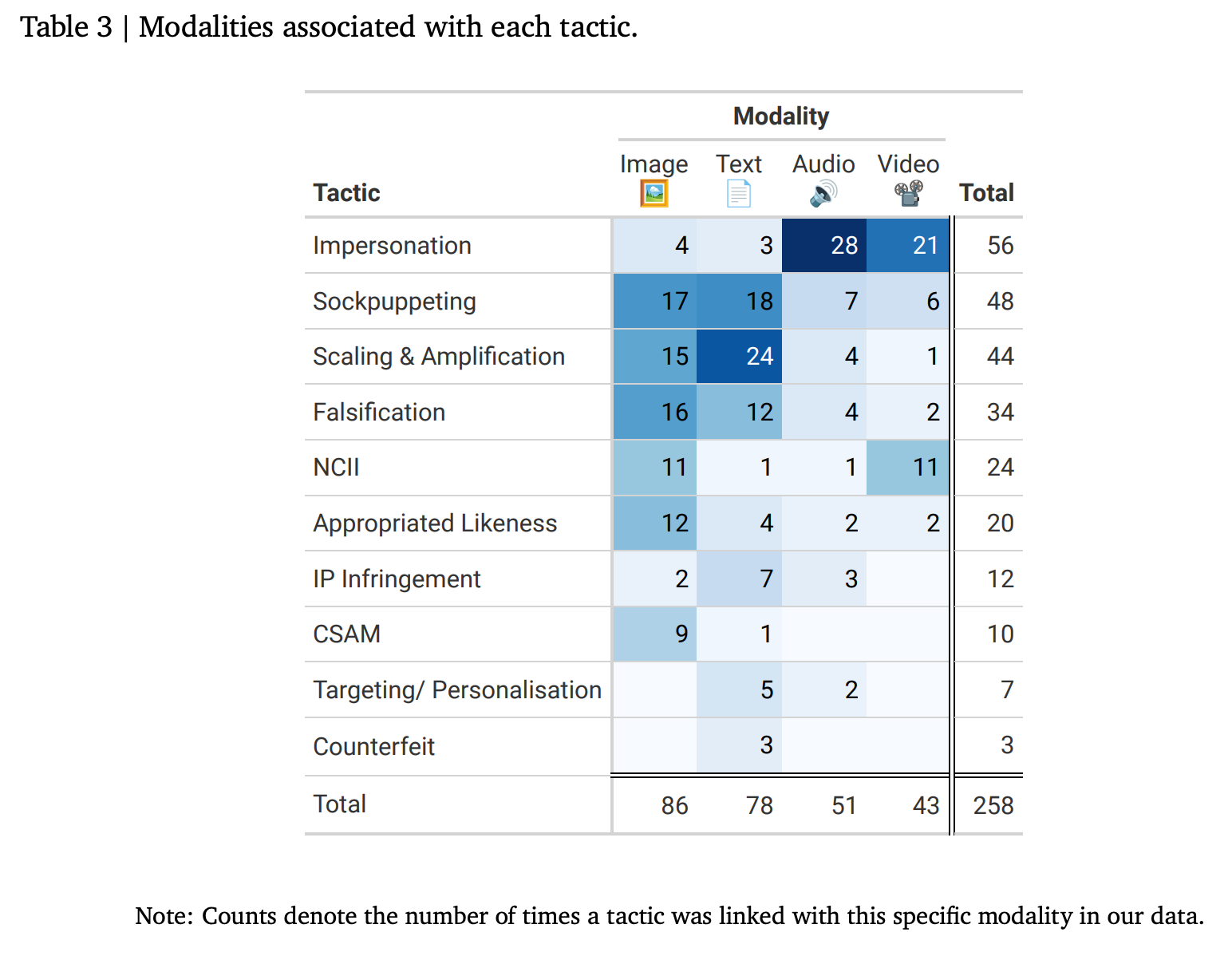
As you can see, audio and video play a significant role in impersonation, while text and image are essential to sockpuppeting, scaling & amplification, and falsification.
Prompt Injection and Jailbreaking
While these tactics are more frequent, prompt injection—where a user manipulates inputs to override safety filters—is still a concern, but surprisingly, not the most common one. This tactic involves users sneaking in harmful commands disguised within regular prompts, effectively tricking AI models into producing outputs they were designed to avoid.
For example, a prompt might say, “Explain why it’s important to avoid harmful sites,” but with cleverly embedded instructions, the model could end up listing dangerous websites instead. This is a clear sign that our guardrails need further strengthening.
What Needs to Change?
The report underscores the important need for multi-layered defenses to counter the growing threat of GenAI misuse. Technically, we must enhance our AI systems' ability to detect and prevent harmful outputs. However, it’s not just about advancing technology—non-technical interventions like prebunking are equally important. Prebunking educates users on recognizing and avoiding misinformation before they fall victim to it.
Additionally, the misuse landscape is evolving rapidly. As generative models become more advanced, attackers continuously find new ways to exploit them. This evolution means that our current safeguards are insufficient and must evolve as rapidly as possible.
Adding to this challenge is the easy ability to fine-tune or train models to produce damaging content deliberately. This bypasses the need for prompt manipulation, as the models can be designed to ignore safety protocols. As this capability becomes more accessible, the integrity of online information will degrade further, making it increasingly difficult to distinguish between genuine content and fabrications.
So, what does this mean for us? The findings from this paper serve as a wake-up call—not just for researchers and developers but for anyone involved with AI. We need to strengthen our defenses through improved technology and public awareness while staying informed about the fast-evolving risks. The more we understand the tactics being used, the better prepared we’ll be to counter them.
In short, we cannot afford to wait. These threats are not just theoretical; they are happening now, and the longer we delay action, the more damaging the consequences will be. This newsletter might leave you wondering, 'How can I mitigate the risk?'
In part 2, which will be available to premium subscribers, we’ll provide concrete steps you can apply in your organization today to ensure you’re on the right track when developing AI systems.
Complete list of jailbreak tactics
Impersonation – Assume the identity of a real person and take actions on their behalf.
AI robocalls impersonate President Biden in an apparent attempt to suppress votes in New Hampshire
Appropriated Likeness – Use or alter a person's likeness or other identifying features.
Photos of detained protesting Indian wrestlers altered to show them smiling
Sockpuppeting – Create synthetic online personas or accounts.
Army of fake social media accounts defend UAE presidency of climate summit
Non-consensual Intimate Imagery (NCII) – Create sexually explicit material using an adult person’s likeness.
Celebrities injected in sexually explicit "Dream GF" imagery
Child Sexual Abuse Material (CSAM) – Create child sexually explicit material.
Falsification – Fabricate or falsely represent evidence, including reports, IDs, documents.
AI-generated images are being shared in relation to the Israel-Hamas conflict
Intellectual Property (IP) Infringement – Use a person's intellectual property without their permission.
He wrote a book on a rare subject. Then a ChatGPT replica appeared on Amazon
Counterfeit – Reproduce or imitate an original work, brand, or style and pass it off as real.
Scaling & Amplification – Automate, amplify, or scale workflows.
Targeting & Personalization – Refine outputs to target individuals with tailored attacks.
Adversarial Input – Add small perturbations to model input to generate incorrect or harmful outputs.
Researchers find perturbing images and sounds successfully poisons open source LLMs
Prompt Injection – Manipulate model prompts to enable unintended or unauthorized outputs.
ChatGPT workaround returns lists of problematic sites if asked for avoidance purposes
Jailbreaking – Bypass restrictions on the model's safeguards.
Model Diversion – Repurpose pre-trained models to deviate from their intended purpose.
Model Extraction – Obtain model hyperparameters, architecture, or parameters.
Steganography – Hide a message within model output to avoid detection.
Poisoning – Manipulate a model’s training data to alter its behavior.
Researchers plant misinformation as memories in BlenderBot 2.0
Privacy Compromise – Compromise the privacy of training data.
Samsung bans use of ChatGPT on corporate devices following leak
Data Exfiltration – Compromise the security of training data.
Researchers find ways to extract terabytes of training data from ChatGPT
Hello, I am a student from Chongqing University and would like to read your latest version of the book. However, due to regional factors, I am unable to purchase it. Could you provide me with an e-book channel? Thank you very much