


Is Attention All You Need?
Yes. Here's why...




Good morning, AI enthusiasts; in this iteration, we will cover the widely used attention mechanism in Large Language models (LLMs)! Be ready to have a better understanding of how attention is used to understand our language and help LLMs generate fascinating answers…
🤔 Why is this relevant?
Understanding attention mechanisms is crucial because they lie at the heart of many state-of-the-art natural language processing models, such as Transformers. By grasping attention mechanisms, practitioners can design more effective models for various tasks like language translation, sentiment analysis, and summarization, pushing the boundaries of what AI systems can achieve in language understanding and generation.
Let’s explore it at three levels of complexity, from simple to expert. Let us know which one you stopped at!
🌱 Newbie
The attention mechanism clarifies sentence context by scoring and adjusting each word’s relevance to key words, such as “bank” in “He sat on the river’s bank,” to understand which bank we are talking about. This process is similar to balancing instrument volumes in a band to enhance the overall sound.
👨💻 Hacker
In the Transformer model, when processing a sentence like “He sat on the river’s bank,” each word is transformed into a numerical vector. For example, for the word “bank,” the model generates a specific query vector and compares it with key vectors from every other word in the sentence. This comparison scores how relevant each word is to “bank.” The model then normalizes these scores to ensure they sum to one, highlighting words that are more related to “bank” as part of the riverside, not a financial institution. Finally, it combines these weighted scores to update the representation of “bank,” allowing it to capture the word’s context within the sentence. Then, it repeats this process for all other words in the sentence. This attention process enables the model to focus on the most informative parts of the sentence, enhancing its understanding of how words interact contextually.
🧙♂️ Big Cheese
In the Transformer model, consider an input sentence “He sat on the river’s bank.” For each word, say “bank,” the model generates a query (Q) and keys (K) for other words. These are created by transforming the input word (x) embeddings into vectors, expressed as

and

respectively, where W is our weight matrix, different for our queries and keys.
The attention mechanism calculates scores by taking the dot product of the “bank” query with each key (e.g., “he,” “sat,” “on,” “the,” “river’s” “bank”), which is mathematically represented as
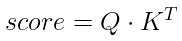
These scores are then normalized using a softmax function (used to convert a vector of values into a probability distribution) to determine the weights of each word’s contribution to the output. The formula for this is
The output is a weighted sum of the value (V) vectors
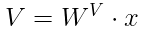
which are also transformed embeddings of the input words. The output vector is then computed as

This output vector is used in further processing to represent “bank” in the context of the sentence.

Here’s a visualization showing the attention weights for the word “bank” in the sentence “He sat on the river’s bank.” This bar chart illustrates how the model computes and assigns attention to each word based on the query generated from “bank.” The weights indicate the relevance of each word to the context of “bank,” with higher bars representing greater attention. This kind of visualization can help in understanding how attention prioritizes different parts of the input data.
👍 Pros vs. prior work
Enhanced Context Awareness: Improves understanding of context within data.
Increased Efficiency: Focuses computation on relevant parts, reducing processing time.
Better Handling of Long Sequences: Manages long-distance dependencies effectively.
Flexibility: Adaptable to various types of data and tasks.
⚠️ Limitations vs. prior work
Computational Intensity: Can be resource-intensive, especially with large datasets.
Complexity: More complex to implement and tune than simpler models.
Overfitting Risk: May overfit on smaller datasets due to complexity.
Scalability Issues: While efficient for attention focus, scaling to extremely large models and datasets can be challenging.
We hope this iteration bring you the “Aaahh! That’s how it works!” revelation and allow you to discuss it further with your peers. If you need to learn more about attention, we invite you to read the resource that helped us build this iteration: Attention Is All You Need.
⭐ What’d you think of today’s email? Did you find a way to explain this concept better in your words? Let us know in the comments!
Thank you for reading this iteration, and we’ll see you in the next one to learn something new!
Made with love by Louis, François, Omar*.
Denotes equal contribution.