


#22 Smaller, Faster, Smarter: The Power of Model Distillation
Why OpenAI’s New Approach Challenges the Open-Source AI Community




Good morning everyone!
Last week, we covered OpenAI’s new series of models: o1. TL;DR: They trained the o1 models to use better reasoning by leveraging an improved chain of thought before replying. This made us think. OpenAI enhances reasoning by having the model generate tokens that aren't visible to users. It then uses this to generate the actual response. This decision significantly impacts the future of large language models (LLMs).
Today, we're exploring an important technique in LLMs: model distillation. This approach has become increasingly crucial as LLMs grow larger, allowing us to capture some of their impressive capabilities in more manageable packages.
In this iteration, we will cover model distillation and why OpenAI’s decision is highly important for this approach and the future of language models.
First, what is model distillation? Model distillation is a technique to transfer knowledge from a large, complex model (the "teacher") to a smaller, more efficient model (the "student"). The goal is to create a compact model that retains much of the performance of its larger counterpart.
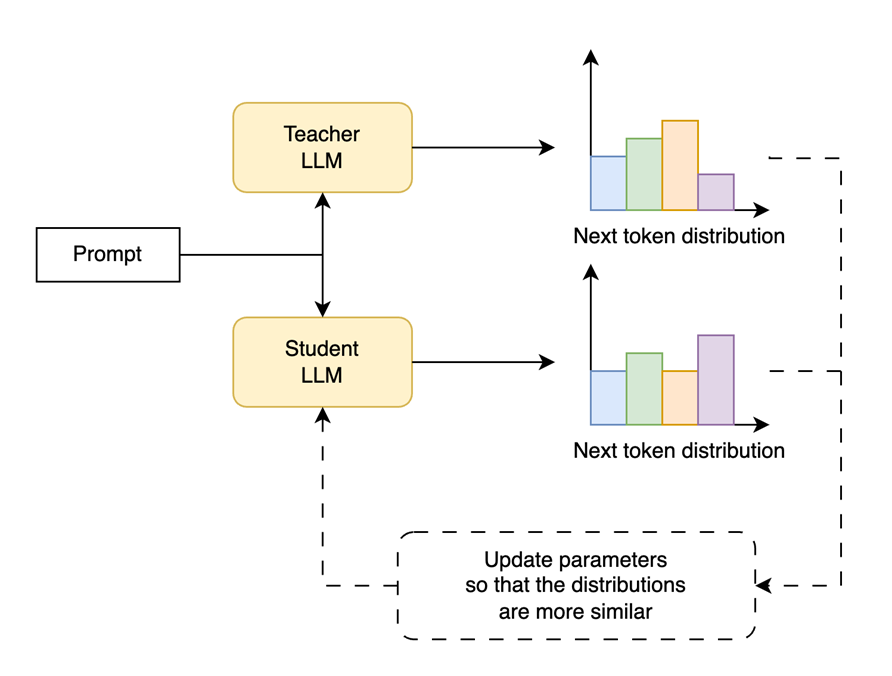
A prompt is sent to both the teacher and student language models, which predict the next token (or next word). Then, we update the student model to better follow the teacher's prediction. We do that in the “token distribution” probability space rather than with words, but it is also possible to do it with the actual predictions if you are working with proprietary LLMs (e.g. through APIs) through less powerful—image from the “Building LLMs for Production” book.
How Does it Work?
Train the Teacher: First, a large model is trained on a vast dataset, becoming highly capable but computationally expensive.
Generate Training Data: The teacher model labels a large dataset. So the small model can copy the bigger model output.
Train the Student: A smaller model is then trained to mimic the teacher's outputs, matching the same word (or token distribution) predictions. This allows the student to learn not just the correct answers, but the nuanced "reasoning" behind them.
Fine-tune: The student model may be fine-tuned to recover some lost information in the process or it could be fine-tuned for specific tasks.
The key insight is that the teacher token prediction distribution contains more information than just the final predicted label (the token or word), allowing for more effective knowledge transfer.
💡 Token prediction distribution: This is a distribution of which token seems the best fit to predict next and by how much, such as in the sentence “Who let the dogs …”, here “out” might have more weight than “in” in the prediction distribution.Distillation allows us to create smaller models that are:
Faster to run
Less computationally expensive
Easier to deploy on edge devices or in resource-constrained environments
Retain similar capabilities (if not better at specific tasks) as the teacher
The Llama and Gemma suite of models is trained by leveraging model distillation from the bigger model (Llama 405B or Gemini, respectively).
On the other hand, OpenAI has made the significant decision, with its new o1 reasoning models, to hide the model's reasoning steps and present only a summary of each reasoning step in the output.
While this choice may enhance safety and monitoring capabilities (as they claim in their system card), it poses substantial challenges for the open-source community.
Researchers and developers outside OpenAI now face greater difficulty understanding the model's decision-making process and performing knowledge distillation. Not only that, but we don’t have access to the model’s token distribution or the first generated tokens anymore, which makes it practically impossible to distill the o1 series into a new suite of similarly-capable models.
This decision potentially widens the divide between proprietary and open-source AI technologies.
It is hard to say what will happen when balancing intellectual property protection with the advancement of open scientific progress, and we simply hope some bigger companies, such as Meta, keep their approach open.
