


Teaching AI to "Think": The Self-Taught Reasoning Revolution
An overview of test-time computation and self-improvement strategies




Good morning, everyone!
Like everyone else, last week, we talked about OpenAI's newest o1 model series, exploring how it leverages an interesting paradigm in AI with test-time computation or, more simply, "reasoning."
We discussed how o1's ability to adapt its reasoning process in real-time could lead to more flexible and robust AI systems, particularly valuable when the model encounters novel or complex problems. Unfortunately, such “reasoning” has a big limitation in time for generation (latency) and cost (needs to generate many more tokens before answering).
💡 Recap: OpenAI's o1 Model Series
OpenAI's o1 model series introduces test-time (when users exchange with the model) computation with an LLM in a production environment. This allows the models to perform additional reasoning steps (at inference time) before generating a final answer.One of the key issues with our current approach to AI reasoning can be summarized by the quote: "We teach the machines how we think we think." It reflects a deeper flaw in training models based on human intuition, which isn’t necessarily how reasoning truly works (nobody knows). This opens up a broader discussion about how machines can independently develop reasoning skills rather than merely mimicking human approaches.
Building on that foundation, we'd like to share some exciting developments reshaping how AI models might learn to reason. These advancements center around self-taught reasoning, where AI models enhance their capabilities by learning from their own reasoning processes.
Improving an AI model's reasoning capabilities traditionally required large datasets annotated with human reasoning steps (or using chain-of-thought prompting techniques, which had to be mentioned every time and couldn’t be improved during the model’s training). Using annotations is time-consuming and costly, limiting the model's exposure to diverse problem-solving strategies. It relies heavily on human expertise to guide the model's learning, which can be a bottleneck in terms of pricing when we need large datasets in the gazillion number of words.
What about having AI models teach themselves to reason more effectively? Instead of depending on extensive human-annotated data, one could use reinforcement learning techniques with a relatively small dataset and use the model’s own generated reasoning steps to improve over time. This self-improvement loop allows models to become more intelligent and capable by learning from their successes and mistakes.
Building on the concept of self-taught reasoning in AI, a recent approach, SCoRe (Self-Correction via Reinforcement Learning), offers a significant advancement that closely mirrors the functioning of OpenAI’s o1 model series. Like o1, SCoRe enables models to self-correct during inference by iteratively refining their responses through multi-turn interactions. Instead of relying on large, pre-annotated datasets, SCoRe allows models to improve their performance using self-generated data, refining their reasoning step by step during inference. By shaping the learning process with rewards that emphasize successful corrections, SCoRe aligns with the o1 model’s ability to adjust its reasoning in real time, making both approaches highly effective for solving complex and novel tasks. Here’s an image showing how SCoRe works from the paper:
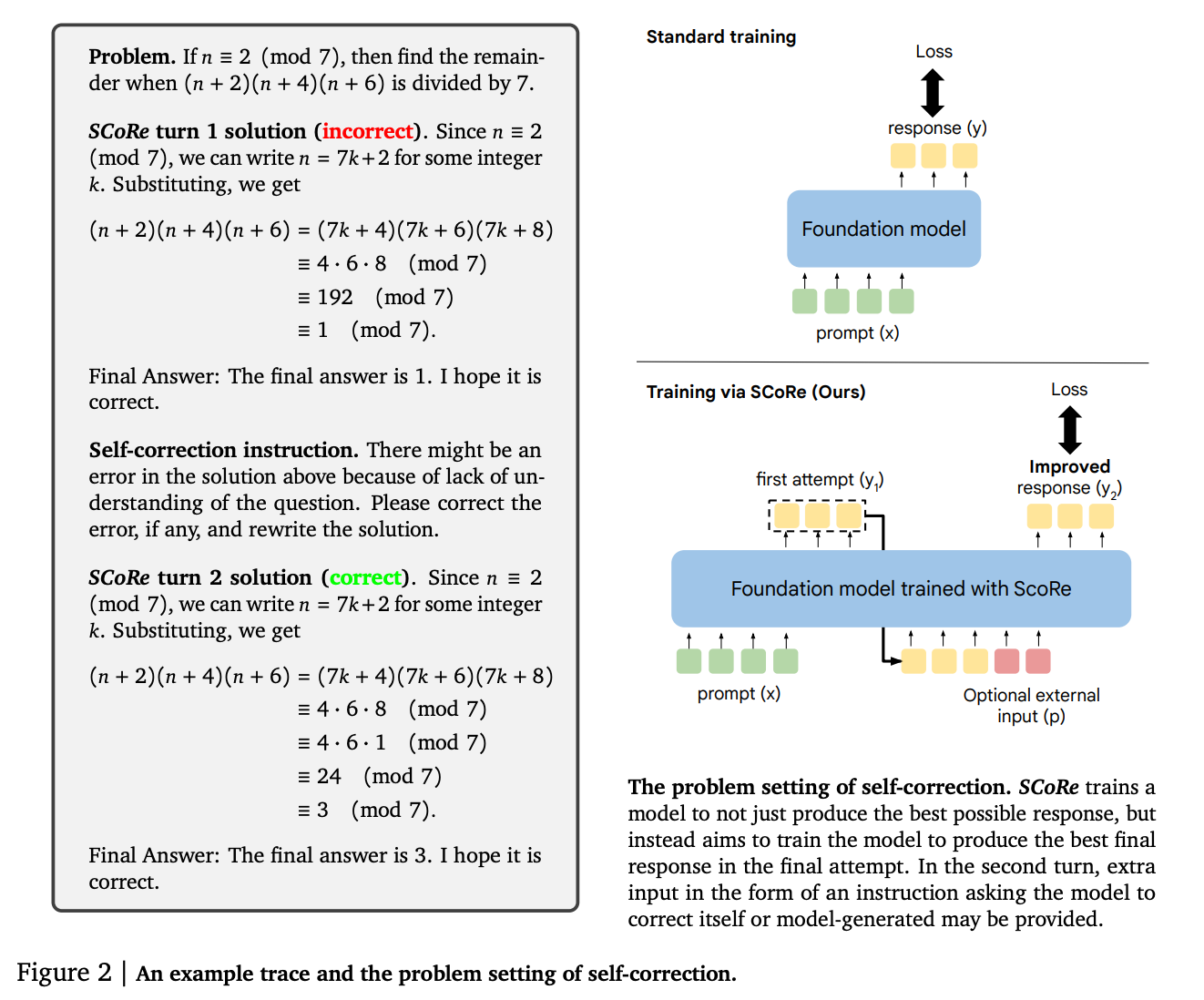
Example of self-correction self-discussion in o1:

The key to making AI reasoning more effective lies in teaching models three important things: 1) General knowledge (e.g., languages or mathematical principles), 2) Self-awareness—knowing when they don’t know the answer, and 3) Task execution live at inference, where models dynamically learn and adapt to tasks in real-time rather than pre-learning all possible tasks. This dynamic learning at inference opens new doors for handling unforeseen challenges efficiently.
Great! Reinforcement learning (RL) + high-quality data + scaling = big brain. Seems like magic. How can this be done in practice?
💡 Reinforcement learning is just the cherry on the cake (as Yan LeCun said). It’s merely an optimization layer on top of a functioning algorithm. It’s not groundbreaking or foundational work, but it can still improve specific areas, such as test-time reasoning.
p.s., progress in AI reasoning isn’t just about reinforcement learning. Progress = less structure + more compute + more data. We’ve seen that loosening the rigid frameworks in which models operate, while simultaneously increasing their access to data and computational resources, leads to surprising breakthroughs.One of the foundational works in this area is the Self-Taught Reasoner (STaR) approach, introduced by Zelikman et al. (2022). The STaR approach enables models to bootstrap their reasoning abilities using a small set of examples rather than relying on massive datasets with human-annotated reasoning steps.
The model attempts to solve problems by generating step-by-step explanations, or "rationales." It then keeps the rationales that lead to correct answers and fine-tunes itself on these successful examples, progressively tackling more complex tasks.
Building upon STaR, Verification for Self-Taught Reasoners (V-STaR), proposed by Hosseini et al. (2024) (from our friends at Mila! 😀), introduces a "verifier" component within the model. This verifier helps the LLM (the generator) assess the quality of its own reasoning. The model generates multiple reasoning paths for each problem, using both correct and incorrect solutions to train the verifier.
The verifier learns to distinguish between effective and ineffective strategies, improving the model's ability to select the most accurate and efficient reasoning path when faced with new tasks. We then simply generate multiple potential responses in the “thinking process” and use the verifier to select the best one, which we do iteratively to train the LLM to “think better.” V-STaR is probably what OpenAI used (or something similar) to train o1.
💡 This highlights a critical concept in AI development: Scaling = replacing current bottlenecks with more scalable options. By identifying and removing constraints in how models are trained and fine-tuned, such as pre-training limits or latency issues during test-time computation, we can scale AI performance more efficiently. And as each bottleneck is addressed, the next challenge emerges, but the system continues to improve.A recent study (by Google Deepmind) emphasizes that scaling test-time computation can be more efficient than scaling pre-training efforts. For example, in certain cases, applying additional computation during test-time—through methods like compute-optimal search—has been shown to outperform models that are 14x larger in pre-training size. This suggests that rather than solely focusing on pre-training massive models, we can make significant performance gains by strategically allocating computation resources during inference.
This mirrors approaches used in models like V-STaR and likely OpenAI’s o1 model, where a balance is struck between test-time compute and pre-training scale, optimizing the probability of giving you correct answers during deployment.
Another innovation that made a bit less noise is Quiet-STaR, again published by Zelikman et al. (2024). Quiet-STaR introduces an interesting mechanism where the model generates 'internal thoughts' that are not directly outputted but instead marked with <|startofthought|> and <|endofthought|> tokens. These tokens indicate when the model starts and finishes its reasoning process, similar to how models use <|endoftext|> tokens to signify the end of a generation. This 'quiet' reasoning occurs outside the direct output stream but significantly enhances predictions, much like what o1 does. Unlike V-STaR, which uses a verifier, Quiet-STaR relies on a reinforcement learning method called REINFORCE to optimize its reasoning process. In this setup, the model generates several potential thoughts and receives feedback on which thoughts were helpful for solving the problem. This allows the model to iteratively improve its internal reasoning, ensuring that future decisions are based on more refined thinking.
Just as o1, these self-taught reasoning approaches enable models to improve their reasoning capabilities through iterative self-improvement. The o1 model's reinforcement learning approach allows it to identify and rectify errors in a chain of thought, resulting in more resilient reasoning. This mirrors how STaR, V-STaR, and Quiet-STaR models learn from their own reasoning processes to enhance performance.
Why is this important for us?
Models trained with self-taught reasoning can tackle more complex tasks that require multi-step thinking, such as strategic planning, data analysis, or nuanced customer interactions. They are better equipped to handle new and unforeseen challenges, making our systems more adaptable and resilient.
This approach reduces dependence on large, annotated datasets, saving time and resources. Unfortunately, it also requires more computational power during inference—a concept now known as "test-time compute."
As we discussed with the o1 model, increasing test-time computation allows the model to perform additional reasoning steps during deployment (vs. train-time compute, see image below), leading to better performance on complex tasks.

Interestingly, the concept of test-time compute has become a focal point in AI research lately. The latest research suggests that test-time compute—the additional reasoning a model performs during inference—can substitute for more extensive pre-training. Models that employ more efficient test-time computation methods can solve problems that would typically require much larger pre-trained models, potentially saving significant resources and improving model adaptability at scale. Noam Brown, a researcher at OpenAI, asks: What if models could think for weeks to solve a complex problem?
