
Why is Llama 3.1 such a big deal?
10 (+1) questions managers and leaders should know about Llama 3.1



Good morning everyone!
As you probably already know, yesterday, Meta released Llama 3.1, marking a significant milestone in AI, notably for its open-source nature and impressive capabilities (it is the first-ever SOTA open-source flagship LLM).
In this iteration, we wanted to cover this news a bit differently than all content we’ve seen online, focusing specifically on the types of questions managers and others in leadership roles may want or need to know.
So here it is… the 10 (+1) questions you need to know the answers:
Why is Llama 3.1 such a big deal?
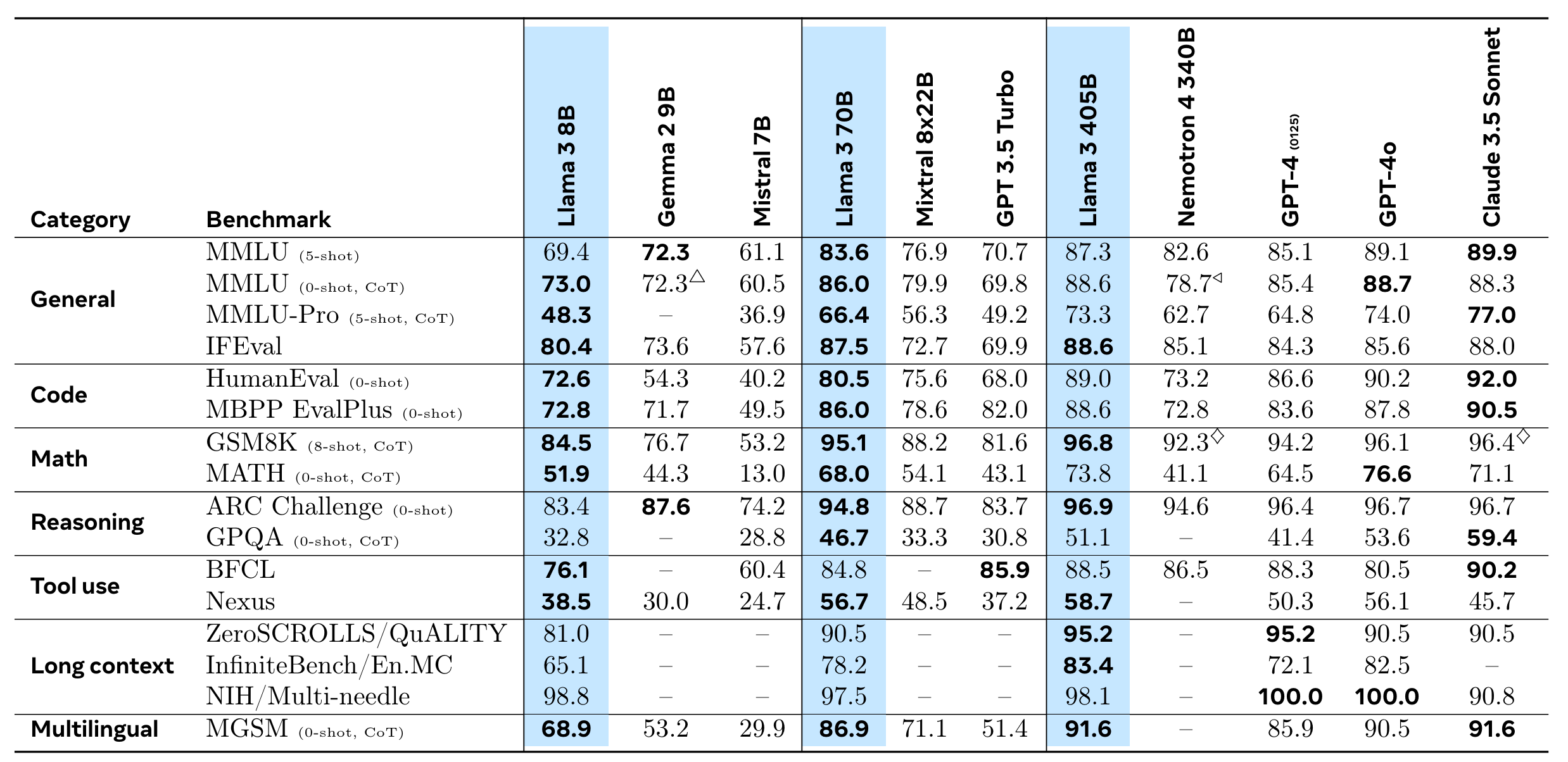
Llama 3.1 is a game-changing 405 billion parameter open-source AI model that supports multilingualism (fun fact, this was an emerging ability from large datasets and works with surprisingly little “other language” data!), coding, reasoning, and tool usage, matching or surpassing closed-source models like GPT-4 (0125) in various benchmarks. Its open-source nature democratizes access to cutting-edge AI technology (following the steps of GPT-2, GPT-Neo, GPT-J), enabling businesses and developers to leverage state-of-the-art language models without vendor lock-in, while its competitive performance and extensive functionality make it highly attractive for researchers and businesses looking to fine-tune and deploy advanced AI at lower costs.
How does the open-source nature of Llama 3.1 benefit compared to closed-source models, and what are the long-term strategic benefits of adopting an open-source AI model like Llama 3.1?
The open-source nature of Llama 3.1 allows for greater customization, transparency, and community-driven improvements, providing organizations the flexibility to fine-tune models to their specific needs without vendor lock-in. Long-term strategic benefits include reduced dependency on single vendors (you don’t want to be dependent on OpenAI), potential cost savings (eg. by hosting a smaller fine-tuned version of it yourself vs. cost per token), better explainability (vs. an API), control over server and inference speed, and fostering innovation through community contributions, ultimately leading to broader economic and societal benefits.
What partnerships and integrations with public cloud providers (e.g., Together AI, Groq, Fireworks, AWS, Azure) are available to support our deployment of Llama 3.1, and how can my team leverage Meta's partnerships with cloud providers to experiment with and implement Llama 3?
Meta has partnered with major cloud providers like AWS, Azure, Google Cloud, and Oracle to make Llama 3.1 easily accessible, offering full suites of services for developers to fine-tune and deploy Llama models. Additionally, up-and-coming LLM providers such as Together AI, FireworksAI, and Groq offer low prices and fast token processing speeds, providing teams with options to experiment and implement Llama 3.1 without significant infrastructure investment while considering cost-effectiveness. Fun fact again: Meta gave Groq access to a weight-randomized version of the Llama 405B model before releasing it to allow them to prepare and optimize the distribution of the model.
What kind of infrastructure and resources are necessary to deploy and run Llama 3.1 models, especially the 405 billion parameter version (also the 70B, 8B)?
For the 405B parameter version, substantial GPU resources are required - up to 16K H100 GPUs for training, with 80GB HBM3 memory each, connected via NVLink within servers equipped with eight GPUs and two CPUs. Smaller versions (70B, 8B) have lower resource requirements, using Nvidia Quantum2 InfiniBand fabric with 400 Gbps interconnects between GPUs, making them more accessible for many organizations, while storage requirements include a distributed file system offering up to 240 PB of storage with a peak throughput of 7 TB/s. Recently, Elie Bakouch (known for training LLMs on Hugging Face) shared that one can fine-tune Llama 3 405B using 8 H100 GPUs.
What specific advantages does Llama 3.1 offer in terms of performance, cost, and potential cost savings compared to closed models like GPT-4o?
Llama 3.1 offers significant advantages in performance, matching or surpassing GPT-4 in many benchmarks, while being more economical to run, with inference operations costing roughly 50% less than comparable closed models like GPT-4o according to an interview with Mark Zuckerberg. The open-source nature allows for more efficient customization and fine-tuning, potentially leading to better performance on specific tasks at a lower cost compared to closed models, while the ability to run the model on-premises or on preferred cloud providers gives organizations more control over their infrastructure costs.
What kind of skills/team does it take to work with Llama models effectively for our specific use cases?
a - For Fine-tuning, training, distilling…
A team needs expertise in machine learning, particularly in natural language processing and transformer architectures. Skills in data preprocessing, model optimization, and distributed computing are crucial. Knowledge of PyTorch and experience with large-scale model training is essential. The team should include ML engineers, ML ops specialists, and developers.
b - For Deploying/using out-of-the-box
For deploying and using Llama models out-of-the-box, the necessary skills shift towards software development and cloud services expertise. Familiarity with cloud computing platforms such as AWS, GCP, or Azure, and knowledge of containerization tools like Docker, are important for setting up and maintaining the model infrastructure. Understanding model inference APIs and optimization techniques for efficient deployment is also essential. Having domain expertise to align the model's output with specific business needs will ensure that the deployments are both effective and relevant to your organization's goals. DevOps professionals or AI engineers with an interest in practical AI applications will be well-suited for this task.
What kind of support and tools are available for fine-tuning, distilling, and post-training Llama 3.1 models to fit our specific needs?
Meta and its partners are working on comprehensive support for fine-tuning, distilling, and post-training Llama 3.1 models, including services from Amazon, Databricks, and NVIDIA for model customization. Companies like Scale.AI, Dell, Deloitte, and others are ready to help enterprises adopt Llama and train custom models with their own data. Techniques like supervised fine-tuning (SFT), rejection sampling (RS), direct preference optimization (DPO), and QLORA + FSDP (available in the TRL Hugging Face library) are used for model alignment, with tools for efficient deployment such as low-latency, low-cost inference servers provided by innovators like Groq. For the 405B model, a minimum node of 8xH100 GPUs is recommended for fine-tuning.
What are the key benefits of synthetic data generation, and how can our organization leverage this for better AI models? What are the potential benefits and risks?
Synthetic data generation offers significant benefits, including lower costs, scalability, and the ability to generate large quantities of high-quality data for AI model training without constraints related to annotator expertise. Organizations can leverage synthetic data to improve model performance through methods like backtranslation for documentation and multilingual capabilities, enhancing both the breadth and quality of training datasets. However, risks include the potential propagation of incorrect data or biases, necessitating robust quality control and verification processes to ensure data fidelity and model reliability.
How should we approach evaluating and benchmarking with Llama 3.1 to ensure they meet our specific business needs?
To evaluate Llama 3.1, you would do the same as with other models. You should conduct a comparative analysis against other models of similar size across diverse tasks, using well-established academic benchmarks and extensive human evaluations. Additionally, developing custom benchmarks and human evaluations relevant to specific business use cases allows for assessing performance on company-specific tasks and data. Ensuring data decontamination and aligning evaluation methods with specific business needs will help guarantee that Llama 3.1 meets performance and functional requirements.
What are the practical applications of the 405 billion parameter model with a 128K token context window, and how can this benefit our business process?
The 405 billion parameter model, with a 128K token context window, allows for the execution of tasks such as complex reasoning, long document summarization, and extensive context-dependent applications. One other key benefit is the ability to distill this large model into smaller models (8B or 70B), as the new license explicitly permits this compared to OpenAI models. We expect this will be the main usage of the larger model as it is hard for individuals and small companies to host it themselves.
What future developments and features can we expect from Llama models, particularly in multimodal capabilities, and how should we prepare for these advancements?
Future Llama models are expected to incorporate advanced multimodal capabilities, including image, video, and speech understanding. We believe organizations should prepare by investing in infrastructure that supports multimodal data integration; staff should brainstorm how to leverage these advanced features and consider how these capabilities could enhance their existing AI applications. Additionally, the open-source community will likely optimize this generation of models, making them faster during inference and reducing compute requirements, leading to smarter and more efficient AI systems.